Choosing Your Deployment Stack: A Framework for Modern Web Apps
Vercel vs Cloudflare Workers vs containers - how to think about control, complexity, and cost. Plus how Woltex deploys with Cloudflare Workers, Convex, and TanStack Start.
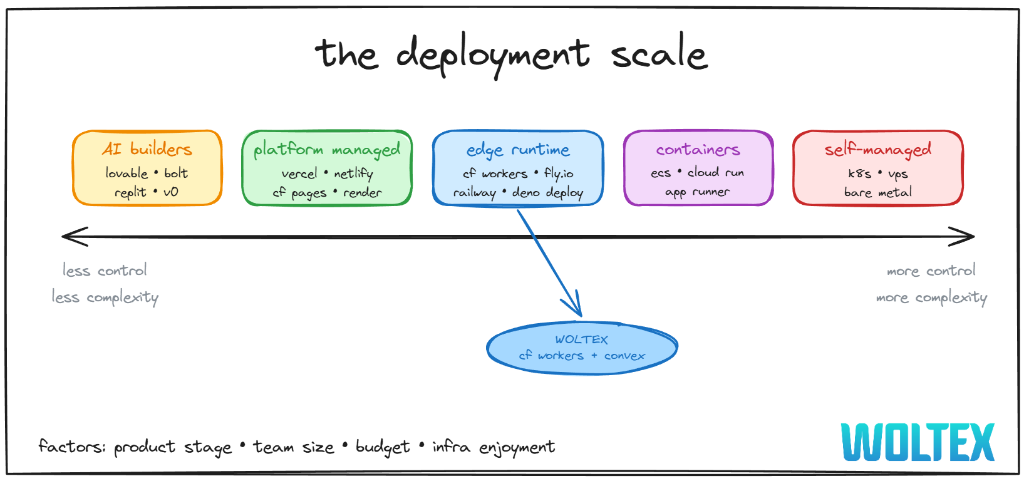
The Deployment Scale
"Should I use Vercel or Cloudflare Workers?" is the wrong question. The real ones: how much control do you actually want? And what happens to costs as you scale?
Building your own edge network is expensive - we're talking millions just for the infrastructure. These platforms let you buy into that capability at a fraction of the cost.
| Category | Examples | Control | Complexity | Cost Model |
|---|---|---|---|---|
| AI Builders | Lovable, Bolt, Replit, v0 | Lowest | Just describe what you want | Per-token / subscription |
| Platform Managed | Vercel, Netlify, CF Pages, Render | Low | Git push and done | Per-request, bandwidth, build minutes |
| Edge Runtime | CF Workers, Fly.io, Railway, Deno Deploy | Medium | More config, more power | Request-based, generous free tiers |
| Containers | ECS, Cloud Run, App Runner | High | Docker, orchestration | Compute + memory + network + LB |
| Self-Managed | k8s, VPS, Bare Metal | Highest | You own everything | VM + network + security + your time |
The right choice depends on: product stage, team size, budget, how much you want to invest in infrastructure, and honestly - how much you enjoy infra work.
Woltex sits in the edge runtime sweet spot: more control than Vercel, less ops than containers.
What is Edge Runtime?
If you've used Vercel, Netlify, or even Lovable - your code runs somewhere. But where? And does it matter?
Traditional deployment looks like this: your app runs on a server somewhere (let's say us-east-1 in Virginia). Every request from Tokyo, São Paulo, or Berlin travels across the ocean to that single location, processes, then travels back. Latency adds up - sometimes 200-300ms just in network travel.
Edge runtime inverts this. Instead of one server handling global traffic, your code runs in 200+ locations simultaneously. When a user in Tokyo makes a request, it's handled by a server in Tokyo. Berlin hits Berlin. São Paulo hits São Paulo.
| Architecture | Locations | Latency | Ops Effort |
|---|---|---|---|
| Single VPS | 1 region | High for distant users | Low |
| Multi-region VMs | 3-5 regions | Better, but gaps | High (sync state, deploy everywhere) |
| Edge Runtime | 200+ locations | ~50ms everywhere | Low (platform handles distribution) |
The tradeoff: edge functions have constraints (execution time limits, no persistent connections). But for SSR (server-side rendering - generating HTML on the server before sending it to the browser) and API routes, they're perfect.
Where Do Apps Actually Deploy?
Following up on the CI/CD pipeline post, this answers the question: where are applications actually being deployed?
The short answer: Cloudflare Workers for the frontend and server-side rendering, Convex for backend logic and database.
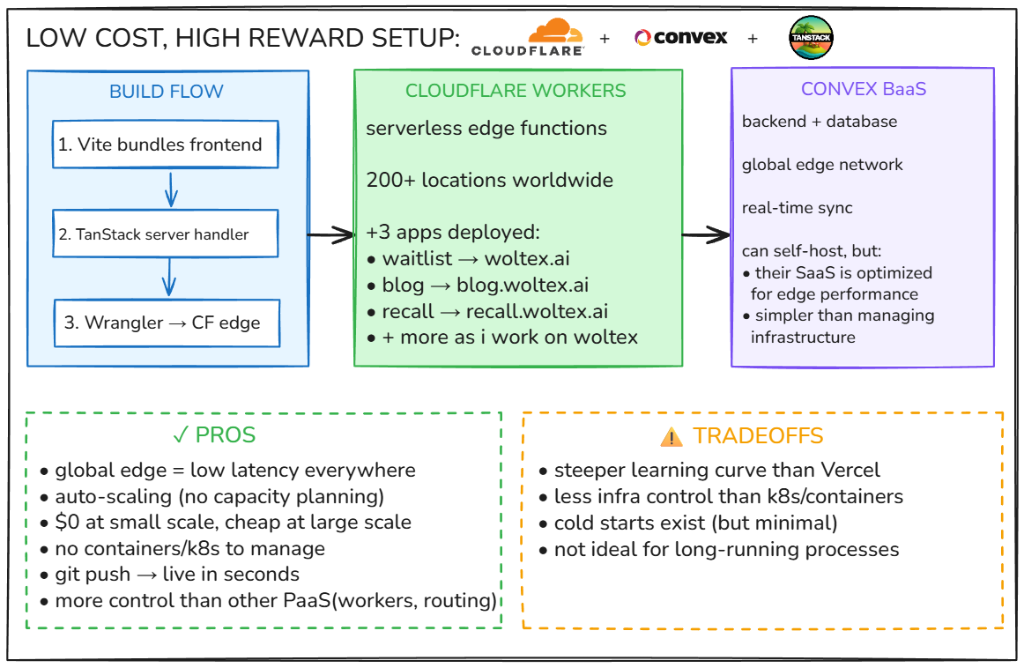
The Stack
| Layer | Technology | What It Does |
|---|---|---|
| Frontend Hosting | Cloudflare Workers | Serverless edge functions at 200+ locations |
| Backend + Database | Convex | Real-time BaaS with global edge network |
| Build Tool | Vite + TanStack Start | Bundles frontend, handles SSR |
| Deployment | Wrangler | Cloudflare's CLI for deploying Workers |
Where's the CDN?
With Workers, there's no separate CDN layer to configure. Workers run at the edge - they're deployed to the same network as Cloudflare's CDN. Static assets are served directly from Workers or via Cloudflare's asset binding, which caches them at edge locations. As you scale, you don't need to add a CDN in front of Workers - you're already there.
Cloudflare Workers
Every Woltex app runs on Cloudflare Workers - serverless functions that execute at the edge, close to users worldwide.
Why are Workers so fast?
Unlike AWS Lambda (which spins up containers), Workers use V8 isolates - the same technology that runs JavaScript in Chrome. Instead of booting a whole container, Workers start a lightweight JavaScript sandbox in ~5ms. This is why Workers have near-zero cold starts compared to Lambda's 100-500ms.
Apps Deployed
| Worker Name | Domain | Purpose |
|---|---|---|
woltexai | woltex.ai | Waitlist + landing page |
woltexai-blog | blog.woltex.ai | This blog |
woltex-recall | recall.woltex.ai | Mob game |
| + others | — | More as Woltex grows |
Each app is an independent Worker. They deploy separately based on which files changed - no monolith deploys here.
Build Flow
Vite Bundles the Frontend
Vite compiles TypeScript/React into optimized bundles:
pnpm --filter waitlist buildTanStack Start Handles SSR
TanStack Start generates a server handler that runs on the edge. This enables server-side rendering (SSR) - your React components render to HTML on the server before reaching the browser, which means faster initial page loads and better SEO.
Why TanStack Start?
Most React meta-frameworks assume Node.js. TanStack Start is built for edge-first deployment - it outputs handlers that run natively on Workers, Deno, Bun, or Node. No adapters, no workarounds. This made it the perfect fit for a Cloudflare Workers setup.
Wrangler Deploys to Cloudflare
The Wrangler CLI packages everything and deploys to Cloudflare's edge network:
npx wrangler deployConvex BaaS
Convex handles the backend - database, server functions, and real-time sync. BaaS (Backend as a Service) means you write your backend logic, but they handle the database, scaling, and infrastructure.
Why Convex?
| Feature | Benefit |
|---|---|
| Real-time sync | UI updates automatically when data changes - no manual refetching |
| Global edge network | Low latency queries worldwide |
| TypeScript end-to-end | Type-safe from database to frontend - catch errors before runtime |
| No infrastructure to manage | They handle scaling, backups, replication |
Convex can be self-hosted, but their SaaS is optimized for edge performance and removes the ops burden.
Edge Functions vs Database Location
Here's a common gotcha: having edge functions doesn't mean your data is at the edge. If your database lives in a single region (say, us-east-1), every query from Tokyo still has to cross the Pacific.
Convex addresses this with their edge-optimized architecture:
- Query functions run close to your users (read replicas at the edge)
- Mutations are routed to the primary database (writes go to one place for consistency)
- Real-time subscriptions use intelligent caching - they track which queries are affected by mutations and push updates only when needed
Watch out if you're DIY-ing: If you're running Workers with a single-region database (like Postgres on a US server), your real-time features will feel that round-trip latency for users in Asia or Europe. This is why choosing a backend with edge-aware architecture matters for latency-critical apps.
Deployment
Convex deploys happen alongside app deployments when backend code changes:
deploy-convex:
if: needs.detect-changes.outputs.convex == 'true'
steps:
- name: Deploy to Convex (production)
if: github.ref == 'refs/heads/main'
run: pnpm --filter @woltex/convex run deploy
env:
CONVEX_DEPLOY_KEY: ${{ secrets.CONVEX_DEPLOY_KEY }}Azure VM (n8n + Monitoring)
Not everything fits the edge model. Long-running workflows, persistent services, and self-hosted analytics need a traditional VM.
| Service | Purpose |
|---|---|
| n8n | Workflow automation with queue workers |
| Prometheus + Grafana | Metrics and monitoring dashboards |
| Rybbit | Self-hosted, privacy-friendly analytics |
All services run on a single Azure VM with zero open ports. Access is secured via Cloudflare Tunnel - no public IPs exposed.
Why a VM for these?
- n8n needs persistent connections, queue workers, and runs workflows that can take minutes
- Analytics (Rybbit) requires a database and shouldn't run on edge functions
- Monitoring needs to store time-series data and run 24/7
For a full walkthrough of the n8n setup, see Production n8n: Queue Workers, Metrics & Monitoring.
Full Deployment Flow
From local development to production:
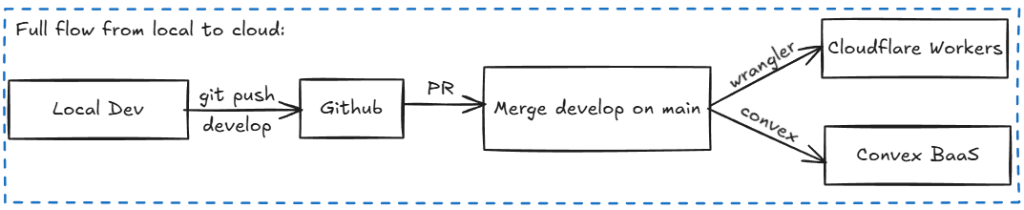
Push to develop
Work happens on feature branches, merged to develop for preview deployments.
PR Checks Run
Lint, type check, security scans - see the CI/CD post for details.
Preview Deployment
Merging to develop triggers preview deployments:
woltexai-preview→ preview.woltex.aiwoltexai-blog-preview→ preview.blog.woltex.ai
Production Deployment
Merging develop → main deploys to production. Live in seconds.
Why This Stack?
Pros
| Advantage | Details |
|---|---|
| Global edge | Low latency everywhere - no regional servers to manage |
| Auto-scaling | No capacity planning, Workers scale to millions of requests |
| Cost-effective | $0 at small scale, cheap at large scale |
| No containers/k8s | Skip the infrastructure complexity |
| Fast deployments | git push → live in seconds |
| More control than PaaS | Direct access to Workers, custom routing, no black-box magic |
Tradeoffs
| Limitation | Reality |
|---|---|
| Learning curve | Steeper than "git push and done" platforms |
| Less infra control | Not as customizable as running your own k8s |
| Cold starts | ~5ms for Workers vs 100-500ms for Lambda - basically a non-issue |
| Long-running processes | Workers have execution time limits (30s free, up to 15min on paid plans) |
30 seconds is plenty for most web requests - API calls, SSR, auth flows. If you need longer (video processing, large file handling, complex AI pipelines), use Convex scheduled functions, Cloudflare Queues, or a traditional server.
Conclusion
This is what works for Woltex - an AI workspace that needs low latency globally, real-time data sync, and fast iteration cycles. Your optimal stack might look completely different.
Building a fintech app? You might prioritize compliance and auditability over edge performance. Running a content-heavy site? A simpler platform-managed solution might be all you need. Shipping a game or collaborative tool? Real-time latency becomes everything.
The framework matters more than the specific choices: understand where you sit on the control-complexity spectrum, know your cost model at scale, and pick tools that match your current stage - not where you hope to be in three years.
Start simple. Migrate when it hurts. Optimize for shipping.
Next Steps
HTTP Security Headers: What They Are, Why They Matter, and How to Fix Them
A practical guide to HTTP security headers for web developers at all levels. Learn what each header protects against, how to implement them in any web app, and a 2-minute fix for Cloudflare users.
Building a CI/CD Pipeline for Monorepos
A secure, multi-stage CI/CD pipeline for pnpm monorepos with automated deployments, security scanning, and OWASP DSOMM compliance.